
Google has released Gemma 4 12B, an open-weight model that takes a different architectural path: it processes text and images together in one unified system, dropping the separate vision encoder that most multimodal models rely on. Instead of bolting a dedicated image-processing module onto a language model, this design folds visual understanding directly into the core network.
Why does the encoder-free approach matter? Traditional multimodal stacks pass images through a vision encoder, convert them into embeddings, and then hand those off to the language model. That adds components to maintain, more places for latency to creep in, and extra complexity when you fine-tune or deploy. A unified model removes one of those moving parts, which can mean a simpler serving setup and tighter integration between what the model "sees" and what it generates.
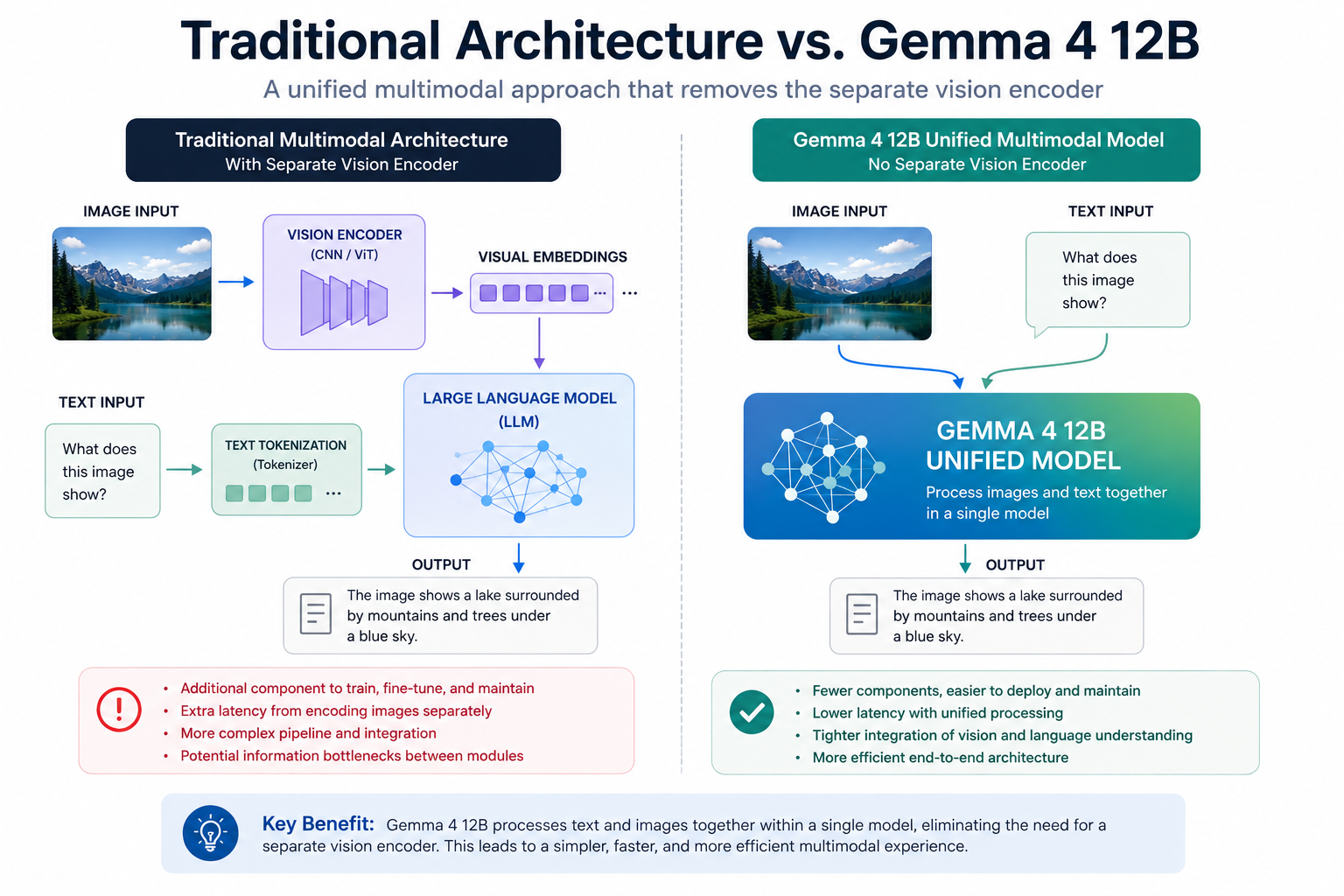
At 12 billion parameters, the model sits in a practical range for teams that want capable multimodal performance without the cost and hardware demands of frontier-scale systems. That size is realistic to run on a single high-memory GPU and fine-tune on modest budgets, which is the whole point of Google's Gemma line: open weights you can actually deploy and customize rather than only call through an API.

For builders, the immediate takeaway is to test it on your own image-plus-text workloads—document understanding, visual question answering, screenshot parsing, or any task where you currently glue an encoder to a text model. Benchmark its accuracy and latency against your existing stack, and check whether the simpler architecture translates into easier deployment in your environment.

As always with new releases, verify the licensing terms and the specifics of multimodal performance before committing. Open weights give you the freedom to inspect, fine-tune, and self-host, but the real test is whether the unified design holds up on your data versus a conventional encoder-based pipeline.